
Contributions dans différents domaines thématiques
M@gm@ vol.5 n.3 Juillet-Septembre 2007
SOFTWARE PER LANALISI QUALITATIVA DEI TESTI
Gevisa La Rocca
gevisa.larocca@futuribile.it
Dottore di ricerca in Sociologia,
territorio e sviluppo rurale (Univ. di Palermo); Ha inoltre
conseguito il D.E.A. (Diploma de Estudios Avanzados, presso
lUniversità dellExtremadura, Spagna); Attualmente collabora
con lIstat allIndagine Campionaria sulle professioni; Allinterno
del LabLav - laboratorio sul lavoro e limpresa della facoltà
di Scienze della Comunicazione (Univ. di Roma La Sapienza)
si occupa dello studio e delle applicazioni delle tecniche
e dei software per lanalisi qualitativa.
1.
Metodi e tecniche di ricerca
Lespressione «Metodologia della ricerca» definisce linsieme
delle discipline che insegnano a condurre una buona ricerca
empirica nel campo della scienze sociali [Ricolfi 1997]. La
ricerca empirica si snoda lungo un suo particolare percorso
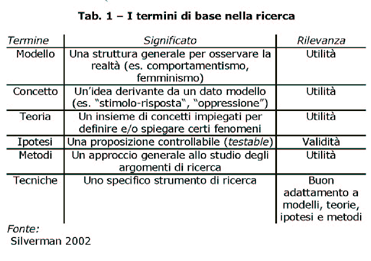
che vede coinvolti a vario livello i modelli, i concetti,
le teorie, le ipotesi, i metodi e le tecniche [Silverman 2000].
I modelli corrispondono, per grandi linee, ai paradigmi; ci
dicono comè la realtà, quali sono i suoi elementi di base
e qual è la natura e lo stato della conoscenza. Al secondo
livello di questo imbuto conoscitivo risiedono i concetti
che derivano dai modelli stessi e sono identificabili come
idee definite in modo chiaro. La nostra intuizione, celata
dietro la ricerca di un modello, diventa sempre più chiara
e operazionalizzabile man mano che attraversiamo i termini
di base utilizzati nella ricerca. E alla teoria che spetta
il compito di fare in modo che insiemi di concetti definiscano
e spieghino dei fenomeni.
La teoria diviene il supporto per comprendere il mondo, separata
dal mondo oggetto di ricerca ma al contempo su quel mondo
stesso proiettata. In questo modo la teoria fornisce una struttura
alla quale riferirsi per una comprensione critica del mondo
e per organizzare quanto si vuole conoscere. Dalla teoria
scaturiscono le ipotesi, che devono essere formulate secondo
criteri che ne permettano la controllabilità e la falsificabilità
[Popper 1970]. Il metodo definisce il modo secondo il quale
si dovrebbe affrontare lo studio dei fenomeni, permettendo
allosservatore di rendere operativi i concetti in uno spazio
di ricerca quantitativo o qualitativo.
Scelto il metodo, occorre definire la tecnica di analisi e/o
di indagine. I sei livelli che sono stati qui indicati come
essenziali nella strutturazione di qualsiasi ricerca empirica
ben condotta non ci permettono di distinguere fra approcci
e disegni di ricerca differenti, fra spazio della ricerca
quantitativa versus spazio della ricerca qualitativa.
Secondo Ricolfi [1997] le ricerche afferenti allo spazio quantitativo
si qualificano per almeno tre caratteristiche:
- limpiego della matrice dati;
- la presenza di definizioni operative dei «modi» della matrice
dati (perlopiù casi e variabili);
- limpiego della statistica o dellanalisi dei dati.
In una costruzione dellidentità per differenza le caratteristiche
ascrivibili alla ricerca qualitativa consistono:
- nellassenza della matrice dati;
- nella non ispezionabilità della base empirica;
- nel carattere informale delle procedure di analisi dei dati.
Privilegiando i percorsi di ricerca qualitativa ed esaminando
i tre tratti ad essa attribuiti si nota come il primo e il
terzo di questi elementi siano facilmente riscontrabili tanto
negli studi etnografici che privilegiano losservazione partecipante
quanto negli studi di comunità. In ciascuna di queste tradizioni
la non ispezionabilità della base empirica discende dalle
caratteristiche proprie della ricerca sul campo, per cui fare
ricerca sul campo significa mixare osservazione e partecipazione,
bilanciare e trovare un punto di equilibrio fra «osservazione
partecipante» e «partecipazione osservante» [Ricolfi 1997].
E questa una cultura del visivo, in cui il ricercatore deve
vedere quanto accade, ma tanto nello spazio culturale quanto
nella dimensione qualitativa di analisi esiste un terzium
datur. McLuhan [1962] sostiene che linteriorizzazione dellalfabeto
fonetico traduce luomo dal mondo magico dellorecchio al
mondo neutro della vista, il passaggio a una prevalenza di
esperienze audio-tattili caratterizza loccidente a partire
dalla rivoluzione prodotta dallentrata nel nostro emisfero
della Galassia Gutenberg.
A partire da questa innovazione tecnologica si produce una
differenza sostanziale nella visione del mondo propria di
un bambino occidentale da quella di un bambino africano. In
un esempio presentato dallo stesso McLuhan, la tecnologia
che circonda un bambino occidentale è descritta come essenzialmente
visiva, astratta ed esplicita, dove le cose accadano in un
tempo e in uno spazio continui e uniformi secondo unordinata
successione. Allinverso, il bambino africano vive nel mondo
magico e implicito della parola risonante [1962, p. 41]. E
tuttavia, quando la tecnologia estende uno dei nostri sensi,
una nuova traduzione della cultura si verifica con la stessa
rapidità con cui la nuova tecnologia viene interiorizzata
[ivi, p. 70].
Lentrata nella nostra orbita della Galassia Internet [Castells
2001] produce una fusione tra uditivo e visivo, restituendo
il calore delleternità di un testo scritto per nulla scevro
dalle caratteristiche delloralità. Si può ora distinguere
nel mondo della ricerca qualitativa, che per Ricolfi [1997]
è definito non dallassenza della statistica ma dal carattere
informale delle procedure di analisi, fra ricerche con base
empirica non ispezionabile quale la ricerca etnografica -
per noi riconducibile ad uno spazio esclusivamente visivo
- da una ricerca con base empirica ispezionabile quale la
ricerca su base testuale.
Al riparo dalle avversità climatiche prodotte dalla comunità
scientifica, sotto lombrello di ricerca qualitativa riposano
diversi metodi di analisi e tuttavia essi stessi costituiscono
lossatura dellombrello.
Gli assi che qui si considerano sono prevalentemente:
- la Grounded Theory;
- la Content Analysis;
- lanalisi quantitativa del lessico.
Esse sono per noi methodology nellaccezione che Silverman
attribuisce ai metodi: «un metodo definisce come si dovrebbe
affrontare lo studio dei fenomeni [2000, p. 126]»; ciascuna
di esse implica luso di specifiche tecniche come strumenti
di ricerca.
2. Software e parole
Al di là dellAmore folle fra analisi del contenuto e computer
[Rositi, 1989] la possibilità che la computer aided analysis
ci offre macinando una stringa dopo laltra, individuando,
conteggiando, elaborando [ivi, p.107] è di poter trattare,
sintetizzare e interpretare testi altrimenti non maneggiabili.
I vantaggi che derivano dalluso dallanalisi dei dati qualitativi
mediante computer si possono riassumere in:
- maggiore velocità di manipolazione di una grande quantità
di dati;
- miglioramento del rigore scientifico;
- agevolazione della ricerca di gruppo, favorendo un condiviso
sviluppo di schemi di classificazione coerenti;
- aiuto nelle decisioni di campionamento [Seale 2000].
Il trattamento automatico dei dati testuali laddove sia stato
preceduto da una formulazione di ipotesi e da una ricognizione
di un quadro teorico di riferimento ci consente di operare
una lettura descrittiva ed interpretativa dei dati, che dà
luogo ad una «ermeneutica quantitativa» dei testi [Giuliano
2004].
Esistono diverse tecniche di data analysis. Una delle prime
tecniche utilizzabili può essere rappresentata dallestrazione
delle key word in context (KWIC), che mostra quali parole
si trovano nel testo e il loro contesto duso. Si producono
quindi elenchi di parole, e relative concordanze, restituendo
uninformazione completa sulla variabilità e la coerenza nel
significato e nellutilizzazione delle parole; inoltre si
determina il significato delle parole legandole al contesto
o allidioma utilizzato: questa è uninformazione strutturale
sul testo. Attraverso la lista di frequenze di parole si possono
invece esaminare le parole di maggior uso. Si possono, anche,
creare delle categorie di significato allinterno delle quali
classificare le parole contenute nel testo analizzandone la
frequenza e quindi la copertura/presenza nel testo da parte
della categoria creata [Weber 1990].
Con testi di dimensioni sufficientemente ampie si può passare
a una tecnica di analisi fattoriale o multidimensionale, in
questo caso si utilizzeranno delle procedure matematiche che
riassumono la variazione di molte variabili osservate o misurate
traducendole in un numero minore di variabili sottostanti
o latenti, chiamate fattori. I software dedicati allottenimento
di tali output sono diversi e proporne un elenco risulterebbe
riduttivo.
Per una ricognizione di quelli più accreditati si consiglia
di visitare questi due portali:
- The Content Analysis Guidebook Online, sviluppato dalla
Cleveland State University e dalla Sage Pubblications. Il
sito propone software per la content analysis, per lanalisi
qualitativa, per lanalisi dei video, altri tipi di software
e consente laccesso a risorse bibliografiche e documentarie
- Text Analysis info page, sviluppato da Harald Klein Social
Science Consulting in Germania. Anche qui è possibile trovare
numerose risorse documentarie e informatiche.
I software per lanalisi dei dati qualitativi si possono classificare
utilizzando diversi criteri. Per esempio, si può distinguere
fra quelli che racchiudono un orientamento alla strumentazione
o alla rappresentazione del testo attraverso una classificazione
semantica per tematiche, o per network tematici [Popping 1997].
Lopera di definizione delle strumentazioni informatiche utilizzate
e utilizzabili è quindi vasta e varia, qui si vuole focalizzare
lattenzione sul legame fra i metodi di analisi qualitativa
e le tecniche che da esse discendono. Un software quindi traduce
in procedure informatiche un orientamento di analisi sviluppato
in un determinato contesto teorico. Il tentativo che si vuole
fare è di ricollegare la tecnica racchiusa nelle specifiche
operative di un software alla sua architettura logica ancorata
a un metodo specifico. Lancoraggio che si propone è sintetizzato
nella figura seguente, dove a un metodo è ricondotta una tecnica.
Fig. 1. Schema sintetico dei metodi e delle tecniche
qualitativi proposti
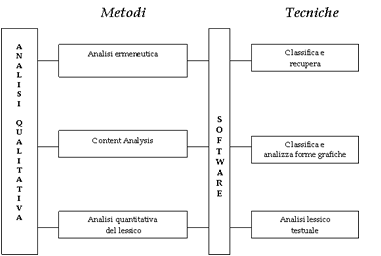
Nello specifico, dallanalisi ermeneutica si fanno derivare
i software che propongono una tecnica definita «classifica
e recupera»: lanalista recupera dal testo le informazioni
a lui necessarie e le classifica secondo unità di significato
da lui create. «Classifica e analizza forme grafiche» sono
le operazioni proprie di quei software dedicati alla content
analysis in cui il ricercatore compie unoperazione semantica
di categorizzazione a partire «anche» dalle forme grafiche
e, in ogni caso, in modo non automatico. Lanalisi quantitativa
del lessico si avvale, invece, di strumenti che consentono
«unanalisi lessico testuale» nella quale si utilizza una
forte base statistica e si pone attenzione allaspetto semantico.
Infatti, lanalisi automatica dei dati testuali classifica,
ma lo fa esclusivamente sulla base delle forme tenendo presente
il contesto e, quindi, anche la semantica.
3. Un software per ogni obiettivo di ricerca
Lapplicazione di una tecnica piuttosto che unaltra produce,
ovviamente, percorsi di ricerca e risultati differenti. Occorre
precisare che ciascuna di esse risponde a obiettivi di analisi
differenti e richiede testi con caratteristiche diverse. Al
fine di illustrare le principali differenze fra gli approcci
si presentano brevemente le tre principali tecniche di analisi
qualitative: Gruonded Theory, Content Analysis, analysis quantitativa
del lessico, considerando lapproccio teorico dal quale discendono,
le tecniche di analisi applicabili, i software e gli output
che questi producono.
3.1 Lapproccio dal basso
Approccio teorico
La Grounded Theory è una teoria sociologica che nasce dai
dati sistematicamente ottenuti da una ricerca [Glaser, Strauss
1967; p. 21]. Questa iniziale definizione apre il testo The
Discovery of Grounded Theory: Strategies for Qualitative Research,
nel quale si legge che per produrre questo «tipo di teoria»
non è necessario ricorrere né allelaborazione statistica
di dati o di informazioni raccolte nel corso dellindagine,
né ad unanalisi delle interviste o delle osservazioni usufruendo
di un qualsiasi supporto che sia di tipo statistico-matematico
[Strati 1997]. La Grounded Theory è infatti tale perché è
una teoria che emerge dal basso, dal «suolo» ed è intenzione
dichiarata di Glaser e Strauss sottolineare in questo modo
ovvero con la scelta del participio passato del verbo to
ground la sostanziale differenza e lontananza della loro
teoria dalla grand theory, con la quale i due studiosi intendono
il «grandioso» approccio sviluppato in seno al metodo ipotetico-deduttivo.
La creazione di una teoria generale fondata sulla stratificazione
di teorie speciali costituisce lobiettivo della Grounded
Theory. Nella Grounded Theory si trovano due tipi di teorie:
«teorie evidenti o reali» (substantive) e «teorie ufficiali
o formali» (formal); entrambe possono essere definite come
teorie di medio raggio.
Alcune caratteristiche di queste teorie vogliono che:
- emergano entrambe dai dati;
- si trovino ad un livello distinguibile di generalizzazione;
- differiscano fra di loro in termini di gradi di generalizzazione;
- le teorie evidenti o di primo livello costituiscano il link
che permette di generare dai dati le teorie ufficiali o di
secondo livello [Glaser, Strauss 1967].
Gli elementi di cui si costituiscono le teorie sono le categorie
concettuali e le proprietà concettuali delle categorie stesse.
Come la categoria è un elemento concettuale proprio di una
teoria, così le proprietà sono, a loro volta, aspetti concettuali
delle categorie.
Tecnica
La generazione di teorie avviene, soprattutto, avvalendosi
del metodo comparativo, il quale può essere applicato su unità
di analisi fenomeni sociali di diverse dimensioni. La
procedura di codifica dei dati consiste - nella sua prima
fase - nellanalisi line-by-line di segmenti, parole, paragrafi,
porzioni di testo. Questo tipo di micro analisi è necessaria
allinizio dello studio per poter attivare il processo di
concettualizzazione e generazione delle categorie e delle
loro proprietà. Lanalisi «riga per riga» dei dati richiede
un dispendio di energie non indifferente ma produce un dettaglio
di studio maggiore rispetto a qualsiasi altro tipo di indagine
condotta sui dati qualitativi. Secondariamente, i dati qualitativi
sono codificati secondo tre modalità distinte:
- la codifica aperta;
- la codifica assiale;
- la codifica selettiva.
La codifica aperta è il processo analitico attraverso il quale
i concetti vengono identificati e le loro dimensioni emergono
dai dati [Strauss, Corbin 1996; p. 101]. Il cuore della codifica
aperta è rappresentato dai concetti; del resto come sostengono
Anselm Strauss e Juliet Corbin non esiste scienza senza
concetti. Open Coding vuol dire quindi «aprire» un testo e
far emergere da esso le idee, le forme comunicative che contiene.
In questo senso il primo passo di questo approccio è la «concettualizzazione»:
un concetto è un fenomeno etichettato (labeled phenomenon)
[Strauss, Corbin 1996; p. 103].
Nel processo di concettualizzazione cè molto dellastrazione:
i dati vengono spezzati in frazioni di avvenimenti, separati
gli uni dagli altri e analizzati nella loro unicità. Nelletichettare
il fenomeno il ricercatore può attribuire un proprio nome,
una propria etichetta a quanto lintervistato dice o a quanto
emerge da un testo oppure può utilizzare le parole stesse
del soggetto; questultimo processo di codifica è spesso definito
come «in vivo codes». LAxial Coding è il processo che collega
le categorie alle sub-categorie, collegando le categorie alle
proprie proprietà e dimensioni [Strauss, Corbin 1996; p. 123].
Nella codifica aperta si lavora sui concetti che emergono
dal testo, nella codifica assiale si lavora sulle relazioni
fra categorie e loro dimensioni. Collegare le categorie alle
proprie dimensioni è nella pratica molto più semplice di quanto
possa sembrare. Strauss e Corbin sottolineano come questa
attività sia già in nuce nella codifica aperta. Lultimo processo
di codifica è rappresentato dalla codifica selettiva, che
è il processo di integrazione e rifinitura della teoria. La
Selective Coding è il momento in cui si individua una categoria
principale e si decide di far ruotare attorno a essa linterpretazione
che dei dati si vuole fornire. Anche in questo momento della
Grounded Theory è necessario, una volta individuata la categoria,
attenersi alla comparazione costante tra questa categoria
centrale e le altre o ulteriori elementi che possano emergere
dai dati qualitativi.
Centrale in questa fase è lindividuazione della categoria
principale, del focus attorno al quale far ruotare la narrazione
di quanto trovato. La categoria centrale è quella che appare
più di frequente nei dati; ha più connessioni con le altre
categorie e la spiegazione/interpretazione che essa fornisce
ai dati appare logicamente dagli stessi, non mediante una
forzatura. Inoltre, la frase o le parole utilizzate dal ricercatore
per indicare questa categoria, quindi il concetto attraverso
il quale la si designa, deve porsi a un livello di astrazione
tale da poter essere attribuito, senza subire cambiamenti
alcuni, sia alla teoria evidente che alla teoria formale.
In questo modo si accresce il potere esplicativo della teoria
fondata. Attraverso un processo di astrazione e utilizzando
i memo che il ricercatore ha man mano prodotto e astraendo
levento analizzato si individua come categoria principale
il «rituale di passaggio».
Software
Si può scegliere di far emergere il significato del testo
usufruendo di diversi software. Atlas.ti, reperibile allindirizzo
https://www.atlasti.com/de/, è uno di questi.
Nellelaborazione del testo le prime operazioni da effettuare
consistono:
- nella creazione di ununità ermeneutica di analisi;
- nellassegnazione del primary document allunità;
- nellapertura del file;
- nella prima codifica del testo.
La prima codifica operabile sul testo è, quindi, la codifica
aperta. Lopen coding avviene selezionando col cursore del
mouse una parte di testo e attribuendo a questo unetichetta.
Cliccando sul tasto destro del mouse è possibile scegliere
se creare un open coding, ovvero una nuova categoria, utilizzare
la porzione di testo evidenziata come categoria, quindi realizzare
un in vivo codes o scegliere da una lista di categorie già
create dal ricercatore. Questultima opzione è attiva dopo
che si è iniziato a codificare il testo. Si sta, quindi, effettuando
una prima lettura del documento e si assiste allemergere
delle categorie. Da questa prima lettura emergono dal testo
con forza, oltre alle categorie, gli spunti di riflessione
e le suggestioni che possono essere raccolte attraverso il
memo; inoltre, la funzione edit comment permette di annotare
i commenti, le perplessità, i dubbi sullattribuzione di alcune
porzioni di testo a una o a unaltra categoria. In questa
prima fase le categorie che emergono possono essere numerose
e a volte i confini fra luna e laltra un po sfumati.
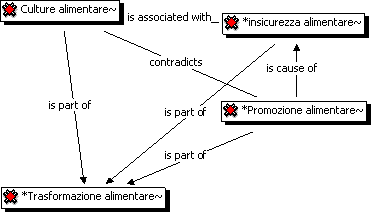
Per stabilire i legami tra i nodi Atlas.ti ha a disposizione
sei differenti tipi di relazioni:
- simmetrica: si stabilisce utilizzando il segno =, cioè «è
associato a»;
- transitiva: si stabilisce utilizzando il segno =>, cioè
«è causa di», che segnala legami causali e processi;
- transitive: si stabilisce utilizzando il segno [ ], cioè
«è parte di» ma anche ricorrendo a isa che sta per «è un»,
entrambe queste funzioni indicano lappartenenza di oggetti
a diverso livello di astrazione e di legami fra concetti specifici;
- legami contradditori: indicati dal segno <>, definiscono
proprietà asimmetriche;
- un elemento di un network è proprietà di un altro referente:
indicato dal segno x} [Sofia 2004, p. 127].
Stabiliti i legami tra i nodi occorre decidere che tipo di
relazione semantica si vuole istituire tra i codici. Atlas.ti
permette di scegliere fra due opzioni:
- un network topologico, che permette di creare una lista
di nodi interni al network, dove i nodi sono disposti secondo
una relazione di dipendenza semantica, la cui visualizzazione
permette di pianificare il progetto delle connessioni tra
i nodi;
- un network semantico, che permette di posizionare i nodi
nel piano utilizzando lalgoritmo semantico, il quale rende
possibile la collocazione dei nodi in una posizione ottimale.
Infatti, tale algoritmo consente di allocare i nodi nello
spazio secondo la più alta connettività rispetto alle posizioni
centrali.
E possibile, quindi, operare secondo due criteri diversi:
visualizzare le direzioni tra i codici usufruendo del layout
topologico che permette di analizzare la dipendenza semantica
tra i codici -, oppure rappresentare le relazioni strutturate
mediante il layout topologico ricorrendo al layout semantico.
Fig. 2 - Output di Atlas.ti
3.2 La Content Analysis
Approccio teorico
Il termine Content Analysis è apparso per la prima volta
stando a quanto riferisce Klaus Krippendorff nella sua trattazione
della Content Analysis [1980, 2004] nel 1961 nel Websters
Dictionary of the English Language. Se per il termine esiste
una datazione ufficiale più difficile è capire cosa debba
realmente riferirsi sotto la dizione Content Analysis, poiché
per «analisi del contenuto» oggi comunemente si intendono
tutti quegli approcci che, per un verso o per un altro, lavorano
sul contenuto di un documento scritto e sullestrazione di
significato da questo. Con i moderni software si potrebbe
arrivare a includere sotto questombrello anche il text mining.
Appare chiaro che adottando questa estensione tutti e tre
i metodi qui trattati potrebbero riferirsi a questo approccio.
Un primo utilizzo della Content Analysis per lo studio dei
testi è rappresentato dallanalisi di una raccolta di novanta
inni religiosi - i Canti di Sion - voluta dal clero della
Chiesa svedese nel XVIII secolo, per evidenziare i contenuti
eterodossi della raccolta in oggetto rispetto ai canti ufficiali
proposti dalla Chiesa [Krippendorff 1980; Losito 1993; Tuzzi
2003; Sofia 2004].
Nellapproccio allo studio dei testi si identifica anche la
modalità di analisi delle lettere dei contadini polacchi condotta
da Thomas e Znaniecki [1920] come un metodo di analisi del
contenuto. Ma è a partire dagli Anni Venti, con lopera condotta
da Laswell [1927] sullanalisi della propaganda politica attraverso
la stampa, che si avvia una sistematizzazione della Content
Analysis. A parere di Laswell le ricerche del tempo erano
deboli da un punto di vista metodologico perché non esplicitavano
le procedure di campionamento, di selezione del materiale,
di costruzione degli indicatori; invece, unanalisi quantitativa
ben gestita avrebbe potuto rassicurare da un punto di vista
della certezza dei risultati [Tuzzi 2003]. Già Holsti [1968]
aveva definito la Content Analysis come lanalisi di qualsiasi
tipo di comunicazione, sia essa un giornale, un diario o una
novella, ma con Laswell [1979] si ha unestensione della definizione
di Content Analysis a metodologia basata sulla «semantica
quantitativa» da applicare a qualsiasi tipo di ricerca che
si proponga di studiare i contenuti di un messaggio.
E nellopera dei padri di questo approccio, quali Laswell,
Berelson e Krippendorff, che è vivo lintento di una sua sistematizzazione
metodologica e di una sua esaustiva definizione; per Berelson
essa «(
) è una tecnica di ricerca capace di descrivere in
modo obiettivo, sistematico e quantitativo il contenuto manifesto
della comunicazione [Berelson 1952, p. 18]». Difficile risulta
però riuscire a distinguere cosa sia il contenuto manifesto
e il contenuto latente di una comunicazione. Il primo è definito
da Berelson come il «comune terreno dincontro» per chi comunica,
per chi riceve la comunicazione e per lanalista (rispetto
al legame proposto da Holsti fra Content Analysis e paradigma
della comunicazione, qui si inserisce un osservatore esterno:
il ricercatore); lanalista, in questo caso, assume che i
«significati» che egli ascrive al contenuto, riducendolo allinterno
di certe categorie da lui create, corrispondano ai «significati»
intesi da chi comunica (lemittente) e da chi poi li riceve
[Berelson 1952]. Si assiste ad unopera di continuità nel
«viaggio» del contenuto del messaggio dallemittente, al ricevente,
allanalista.
Tecnica
Esistono diversi tipi di declinazioni di Content Analysis:
- lanalisi del contenuto quantitativa;
- lanalisi del contenuto come inchiesta;
- lanalisi del discorso o proposizionale [Losito 1993, Sofia
2004].
Tuttavia qui si sceglie di presentare una forma di Content
Analysis vicina alla «semantica quantitativa» e basata:
- sulla creazione di categorie;
- sulluso del computer;
- su una rappresentazione multidimensionale delle categorie
in uno spazio cartesiano.
Per comodità si sceglie quindi di definire questapproccio
«Content Analysis categoriale»; la creazione di categorie
è un elemento già fondante della Content Analysis. La scelta
di utilizzare laggettivo «categoriale» per qualificarla è
da attribuirsi alla possibilità di ottenere e privilegiare
una rappresentazione multidimensionale e di sintesi delle
categorie sugli assi (MDS) e non delle parole (ACL).
Software
Il software scelto per lanalisi è Hamlet® - rinvenibile allindirizzo
https://www.apb.cwc.net/homepage.htm - che permette di realizzare
una rappresentazione grafica multidimensionale delle categorie
create e delle parole in esse contenute. Una delle prime procedure
di analisi consiste nellimmettere nel software il testo da
analizzare e la lista delle categorie e dei termini ad esse
correlate. La procedura di creazione delle liste va ripetuta
per tutte e quattro le categorie individuate; il file così
predisposto viene salvato automaticamente e va poi richiamato
e inserito nello spazio indicato dal nome vocabulary file
name; in questo modo si introduce il vocabolario con cui si
andrà a confrontare il corpus a sua volta inserito nella stringa
text file mane.
Negli applicativi del software, dopo aver contato le parole,
le rispettive frequenze e la distribuzione allinterno del
testo, si procede con unanalisi di tipo cluster. Lanalisi
dei gruppi o cluster consiste in un insieme di tecniche atte
a «ridurre» il numero dei dati, unendo vari dati in un solo
gruppo (cluster) in base a qualche «somiglianza» o «vicinanza».
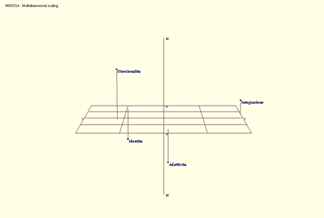
Come si evince dal Minissa Scaling realizzato, la categoria
«Adattività [1]» occupa
una posizione quasi centrale; a lei prossima sono le categorie
«Direzionalità» e «Identità» che si pongono sul lato sinistro;
al margine destro si trova invece la categoria «Integrazione».
Fig. 3 - Output di Hamlet
3.3 La statistica linguistica
Approccio teorico
Lanalisi quantitativa del lessico o statistica dei dati testuali
[Bolasco 2004] si configura come il prodotto dellincontro
di due diverse discipline: la linguistica e la statistica
linguistica. La storia di questa fusione è stata ricostruita
in Italia principalmente da Sergio Bolasco [2004] in un
intervento dal titolo Lanalisi statistica dei dati testuali:
intrecci problematici e prospettive.
La Statistica testuale che noi oggi conosciamo è il risultato
di unevoluzione che ha visto linteresse degli studiosi spostarsi
progressivamente da un piano linguistico quantitativo - si
pensi alla legge di Zipf, alle fasce di frequenza e ai principi
deconomia della lingua - a uno lessicale, fino ad arrivare
ad un approccio lessico-testuale in cui allo studio degli
aspetti testuali di un corpus si accompagna lestrazione di
informazioni linguistiche e si garantisce la possibilità di
effettuare interventi sul testo stesso; fra questi la normalizzazione,
la lemmatizzazione e la lessicalizzazione [Bolasco 1999].
Tecnica
La statistica linguistica ci offre molte possibilità di analisi
sul testo; si può lavorare tanto in ambito lessicale quanto
in ambito testuale. Nellanalisi quantitativa del lessico
si lavora con i corpus. Il corpus: definisce linsieme dei
testi oggetto di studio (fra loro confrontabili sotto qualche
punto di interesse) [Bolasco 1999, p. 182]. Solitamente lo
studio dei corpora è volto ad unanalisi del contenuto o ad
unanalisi del lessico. Tali testi possono essere letti secondo
diversi punti di interesse: in funzione degli obiettivi prefissati
[Tuzzi 2003]. Quando il corpus è costituito da un gran numero
di testi, quando cioè è fortemente differenziato, è difficile
operare con ununica norma [Bolasco 1995, 1999].
Nei casi di corpora di grandi dimensioni, sono necessarie
delle operazioni di pre processing, quali:
- la disambiguazione di forme significative;
- la lemmatizzazione parsimoniosa del testo, per costruire
delle variabili testuali [Bolasco 1995].
Nellesplorazione del testo si può cominciare con lestrazione
delle concordanze: che è lo studio dei contesti locali di
una parola. Con il termine «contesto locale» ci si riferisce
ad un determinato insieme di parole poste a un termine prefissato
- per esempio tra le 5 e le 10 parole prima e le 5 e le 10
parole dopo il termine selezionato - che funge da polo (pivot)
[Bolasco 1999, p. 184].
Lanalisi delle concordanze si effettua su una forma grafica
ritenuta determinante per lanalisi del testo su cui si lavora;
limportanza della forma selezionata si ricava dallindice
gerarchico ottenuto dal corpus (hierarchical index of corpus)
[Lebart et al. 1998]. Ovvero, stabilito attraverso la creazione
del vocabolario quali sono i termini che appaiono nel testo
più di frequente, si può selezionare il frammento di testo
allinterno del quale la forma prescelta appare, per poterne
ricostruire luso o, anche, delineare una mappa concettuale
della parola così per come viene utilizzata nel testo scelto.
In questo modo è possibile esaminare le relazioni concettuali
che sussistono nei vari contesti in cui appare la forma.
La tabella 2 visualizza il risultato delle analisi delle concordanze
con Lexico3; questo software non permette lespletamento di
procedure di pre-trattamento, come accade invece con Taltac.
Tab. 2 - Analisi delle concordanze con Lexico3
| porta qui la bottiglia che proviamo l'abbinamento
tortelli di erbetta porta qui la bottiglia porta qui la bottiglia che proviamo l'abbinamento nador . . . . io pensavo una tagliatella questo . . . ho difficoltà a trovare un abbinamento, se ci fosse Aramis da queste parti potrebbe porta qui la bottiglia che proviamo l'abbinamento tortelli di erbetta porta qui la bottiglia porta qui la bottiglia che proviamo l'abbinamento nador . . . . Annata ? Ris 2002 . . per questo . . . ho difficoltà a trovare un abbinamento, se ci fosse Aramis da queste parti potrebbe tagliolini scalogno e castelmagno bell'abbinamento, attenzione solo a non sparare troppo pepe sentori selvatici. aggiungerei che l'abbinamento migliore per me è uno chardonnay, magari |
Si può lavorare anche sul piano
linguistico, per esempio estraendo mediante Taltac il linguaggio
peculiare o il linguaggio caratteristico. Il linguaggio peculiare
si ottiene confrontando una lista di forme estratto del corpus
su cui si sta lavorando e confrontandolo con una risorsa esterna,
quindi con unaltra lista di riferimento.
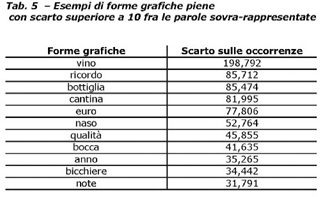
Lindividuazione del linguaggio peculiare avviene in termini
di scarto. E così possibile estrarre le forme peculiari:
parole che risultano avere un forte sovra/sotto uso rispetto
ad un modello di riferimento. La peculiarità si calcola in
termini di specificità intrinseca che può essere sia positiva
che negativa - attraverso uno scarto standardizzato della
frequenza relativa. Così, mediante il calcolo di tale indice,
si procede alla bipartizione delle forme grafiche del vocabolario
in parole chiave sovra/sotto utilizzate - e parole banali,
che presentano cioè uno scarto vicino a zero, e sono quindi
utilizzate con la stessa frequenza tanto nel corpo del testo
che nel modello di riferimento. Si considerano parole banali
quelle aventi uno scarto compreso/uguale a + o 0.9.
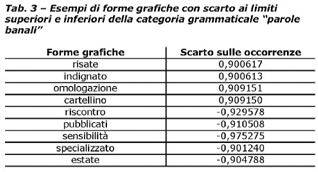
Si considerano parole sotto-rappresentate quelle aventi uno
scarto con valore inferiore a 0.9.

Si considerano parole sovra-rappresentate quelle aventi uno
scarto con valore superiore a +0.9.
Con lanalisi delle specificità, nellidea che P. Lafon [1980]
ne ebbe sul finire degli anni Settanta - ovvero di applicare
una distribuzione ipergeometrica alla questione della ripartizione
delle forme di un corpus - si realizza, invece, una misurazione
del testo nel vero senso della parola. Il corpus viene frammentato
e confrontato nelle sue sub-parti, quindi con una risorsa
interna e non esterna, contrariamente a quanto avviene con
lestrazione del linguaggio peculiare. Qualora sia possibile
suddividere il corpus a disposizione in ulteriori sub-parti,
ciò permette di calcolare la «specificità» di una forma grafica,
lessicale o di qualsiasi altra unità si sia scelta come parametro
di analisi. In questo caso si utilizzano dei parametri di
natura probabilistica che prendono il nome di unità di analisi
caratteristiche o specificità (characteristics elements or
characteristics textual units) [Lebart et al. 1998].
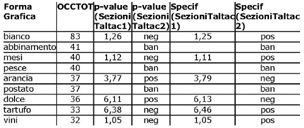
Il coefficiente di specificità indica il livello di significatività
dello scarto rilevato tra la frequenza della forma nella parte
selezionata e le frequenza della stessa forma nelle altre
sub-parti; insomma le specificità permettono di fornire una
descrizione del gruppo di testo selezionato attraverso unità
testuali che, rispetto allintero corpus, si segnalano o molto
più presenti o meno presenti in un dato gruppo piuttosto che
in un altro [Lebart et al. 1998; Tuzzi 2003].
Tab. 6 Esempi di estrazione di analisi delle specificità
4. Riflessioni conclusive
La prima apparizione dei software per lanalisi qualitativa
si è avuta allinizio degli anni Sessanta, ma è stato soltanto
intorno alla metà del 1980 che questi strumenti hanno preso
piede e si sono affermati nelle comunità scientifiche. Di
lì a poco, il rapido diffondersi delle nuove tecnologie e
la comparsa dei personal computer ne avrebbe garantito una
capillare diffusione ed un uso sempre maggiore allinterno
delle comunità accademiche e non [Kelle 2002, pp. 282-283].
Lutilizzo crescente di questi supporti danalisi ha consentito
una loro specializzazione a seconda delle finalità o a seconda
della matrice, e quindi dellapproccio metodologico di ispirazione.
E proprio dei software sviluppati allinterno della Grounded
Theory:
1) garantire uninterpretazione dei testi, siano essi interviste
o documenti, e ricondurli a specifici significati;
2) costruire categorie mediante lestrapolazione dei significati
in essi contenuti e stabilire attraverso il loro studio le
associazioni e le relazioni tra i significati ivi rinvenuti,
in modo da pervenire alla costruzione di teorie generali e
particolari.
Per utilizzare i supporti informatici prodotti in seno alla
Content Analysis è necessario sviluppare e definire unità
di analisi: le categorie, che garantiscano, partendo dalle
forme grafiche, unesplorazione del testo e la descrizione
delle sue dimensioni di senso prevalente. Nonostante questo
approccio ci restituisca «la dimensione prevalente nel testo»
risulta difficile, però, quantificare le osservazioni.
Lanalisi quantitativa del lessico consente di valutare laspetto
morfologico e sintattico del testo, nonché di produrre unanalisi
semantica. Pacchetti come Lexico3 e TaltaC2 consentono: lanalisi
del vocabolario (entrambi), il calcolo di indicatori di ricchezza
lessicale (entrambi), il confronto con risorse linguistiche
esterne (TaltaC2), il calcolo e lestrazione dei segmenti
ripetuti (TaltaC2), il calcolo delle parole caratteristiche
(entrambi), lanalisi delle concordanze (entrambi). Tuttavia,
passando da un software allaltro (da Lexico3 a TaltaC2) ci
si accorge di come la componente statistica aumenti, facendo
venir meno le caratteristiche che secondo Ricolfi [1997] distinguono
lanalisi qualitativa da quella quantitativa, con la prevalenza
in questultima limpiego della matrice dati, la presenza
di definizioni operative dei «modi» della matrice dati e limpiego
della statistica o dellanalisi dei dati. In TaltaC2 lanalisi
qualitativa ha queste caratteristiche; si può affermare, a
ragione, di essere giunti alla statistica dei dati testuali.
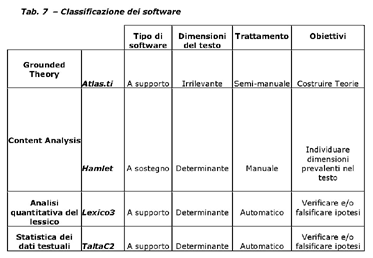
I pacchetti presentati si distinguono per:
- tipo: si intende il contributo che il software dà allanalisi
e può essere a supporto qualora non sia determinante e a sostegno
quando dalloutput dipende lintera interpretazione;
- dimensioni del testo: quando luso del software è limitato
dalla misura del corpus di analisi, si distingue in irrilevante
e determinante;
- trattamento: questa variabile distingue il software utilizzato
in base alla componente manuale, semi-manuale o automatica
in esso utilizzata. Per esempio, lavorando con software come
Atlas.ti ci si accorge di farne un uso semi-manuale, in quanto
il software serve quasi da block notes, ma allo stesso tempo
ci aiuta a stabilire relazioni fra categorie; nel caso di
Hamlet il software in base alle nostre istruzione restituisce
un risultato. E importante notare che nei casi testé citati
il margine dazione della «mano» del ricercatore è prevalente
rispetto alla «forza» del software, cosa che non accade con
Lexico3 e TaltaC2, che sono definiti automatici;
obiettivi: infine, luso delluno o dellaltro pacchetto informatico
dipende, oltre che dal testo con cui si lavora, anche dagli
obiettivi da cui muove lanalisi. Per esempio, è obiettivo
dichiarato della Grounded Theory costruire teorie.
Nel rapporto con lanalisi di un testo la Content Analysis
mira a individuare dimensioni e categorie precedentemente
create prevalenti nel testo. Più complesso è stabilire lobiettivo
dellanalisi quantitativa del lessico e della statistica testuale,
perché le modalità di analisi le permettono di essere ipotetico-deduttiva.
Tuttavia, anche quando si pone degli obiettivi esplorativi
(come di fatto è sempre lanalisi di tipo fattoriale che cerca
di individuare delle dimensioni latenti) questa è comunque
più rispettosa della controllabilità e della replicabilità
dellanalisi.
Una precisazione che ancora occorre addurre è tra la verificazione/falsificazione
di ipotesi e il rapporto di queste con la Content Analysis,
al fine di cogliere la differenza fra questultimo approccio
e lanalisi quantitativa del lessico. Verificare/falsificare
ipotesi sembrerebbe peculiarità dellanalisi quantitativa
del lessico perché per gli output ottenuti da questo approccio
occorre produrre uninterpretazione causale, ovvero un valore
numerico trovato attraverso unoperazione condotta con TaltaC2
non avrebbe motivo di essere se non fosse accompagnato da
una sua interpretazione teorica che lo spieghi e ne dia conto,
appunto. Contrariamente, loutput di Hamlet può semplicemente
essere descritto, non occorre una sua interpretazione, perché
essa risiede nella motivazione sottostante la creazione della
categoria che loutput rappresenta.
Se si guarda a quanto qui esposto in termini epistemologici,
la Grounded Theory ci mostra un orientamento più verso il
contesto della scoperta piuttosto che della giustificazione.
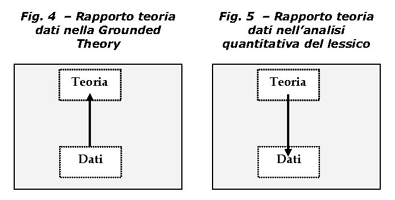
Il rapporto si capovolge se si guarda allapproccio della
statistica testuale e/o analisi quantitativa del lessico.
In questo ideale continuum alla Content Analysis si potrebbe
lasciare un posto intermedio, anche se più propensa alla formulazione
di ipotesi, poiché altrimenti non potrebbe predisporre le
categorie di analisi a priori. A questo punto sembrerebbe
chiaro che il primo approccio, contrariamente al secondo,
rientra nella sfera induttiva, quindi, orientato più al contesto
della scoperta che della giustificazione; viceversa per il
secondo.
Muovendoci allinterno della cultura del visivo, la vicinanza
delle due figure e la direzione discendente/ascendente delle
due frecce fornisce unidea, quasi un «pregiudizio», tra il
primeggiare delluno o dellaltro approccio. Oggi è convinzione
comune sostenere che nessun software sia autosufficiente a
sé bastante e se i software sono espressione di un determinato
approccio teorico, di cui consentono lapplicazione della
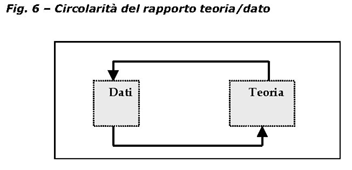
tecnica di analisi, ciò ci conduce come in un sillogismo ad
una sorta di sintesi superiore in cui si accetta la circolarità
del passaggio dalla teoria al dato e dal dato alla teoria.
BIBLIOGRAFIA [2]
Berelson B. (1952), Content Analysis in Communication Research,
The Free Press, New York.
- (1971), Content Analysis in Communication Research, Hafner
Publishing Company, New York.
Bolasco S. (1980), «Analyse des données en tant que antrologie
ou science des subdivision», in Actes des Journées de travail
sur Analyses des Donées, Rencontres franco-italiens, Università
di Napoli, INRIA, pp. 179-193.
- (1994), «Lindividuazione di forme testuali per lo studio
statistico dei testi con tecniche di analisi multidimensionali»,
in Atti della XXXVII Riunione Scientifica della SIS, CISU,
Roma, II, pp. 95-103.
- (1995), «Criteri di lemmatizzazione per lindividuazione
di coordinate semantiche», in Cipriani R., Bolasco S., (a
cura di), Ricerca qualitativa e computer, Franco Angeli, Milano.
- (1999), Analisi multidimensionale dei dati, Carocci, Roma.
- (2004), «Lanalisi statistica dei dati testuali: intrecci
problematici e prospettive», in Aureli Cutillo E., Bolasco
S., Applicazioni di analisi statistica dei dati testuali,
Casa Editrice Universitaria, La Sapienza, Roma, pp. 9-19.
Castells M. (1996-2000), The Information Age: Economy, Society
and Culture, voll. I, II, III, Basil Blakwell, Oxford.
- (2001), Internet Galaxy, Oxford University Press, Oxford
(tr. it. Galassia Internet, Feltrinelli, Milano, 2002).
Giuliano L. (2004), Lanalisi automatica dei dati testuali.
Software e istruzioni per luso, Led, Milano.
Glaser B.G. (1978), Theoretical Sensitivy, Sociology Press,
Mill Valley.
Glaser B.G., Strass A.L. (1964), «The Social Loss of Dying»,
in American Journal of Nursing, n. 64, pp. 119-121.
- (1967), The Discovery of Grounded Theory: Strategies for
Qualitative Research, Aldine, Chicago.
- (1968), Time for Dying, Aldine, Chicago.
Holsti O.R. (1963), «Computer Content Analysis», in North
R.C., Holsti O.R., Zaninovich M.G., Zinnes D.A., Content Analysis:
A Handbook with Application for the Study of International
Crisis, Northwestern University Press, Evanston.
- (1969), Content Analysis for the Social Sciences and Humanities,
Addison-Wesley, London.
Kelle U. (2002), «Computer-Aided Analysis: Coding and Indexing»,
in Martin W. B., Gaskell G. (eds.), Qualitative Researching.
With text, Image and Sound, Sage London, pp. 282-298.
Krippendorff K. (1980), Content Analysis. An Introduction
to Its Methodology, Sage Publication, London (trad. it. Lanalisi
del contenuto, ERI, Torino, 1983).
- (2004), Content Analysis. An Introduction to Its Methodology,
sec. edition, Sage Publication, London.
Lafon P. (1980), «Sur la variabilité de la fréquence des formes
dans un corpus» in Mots, 1 octobre 1980, pp. 127-165.
Laswell H.D. (1927), Propaganda Tecnique in the World War,
Alfred A. Knopf, New York.
Laswell H.D., Kaplan H.A. (1950), Power and Society. A Framework
for Political Inquiry, Yale University Press, London (trad.
it. Potere e società, Il Mulino, Bologna, 1997).
Laswell H.D., Leites N. et al. (1949), Language of Politics:
Studies in Quantitative Semantics, George Stuart, New York
(trad. it. Il linguaggio della politica: studi di semantica
quantitativa, ERI, Torino, 1979).
Lebart L., Salem A., Berry L. (1998), Exploring Textual Data,
Kluwer Academic Publishers, Dordrecht, The Netherlands.
Losito G. (1993), Lanalisi del contenuto nella ricerca sociale,
Franco Angeli, Milano.
McLuhan M. (1962), The Gutenberg Galaxy. The Making of Typografic
Man, University of Toronto Press, Toronto, (tr. it. La Galassia
Gutenberg. Nascita delluomo tipografico, Armando Editore,
Roma, 1976).
- (1964), Understanding Media. The Extension of Man, Mc-Graw
Ill, New York (trad. it. Gli strumenti del comunicare, Il
Saggiatore, Milano, 1967).
McLuhan M., Powers B. (1992) Il villaggio globale. XXI secolo:
la trasformazione nella vita e nei media, SugarCo, Milano.
Popper K.R. (1934), Logik der Forschung, Springer, Wien, (trad.
it. Logica della scoperta scientifica, Einaudi, Torino, 1970).
- (1946), The Open Society and its Enemies, Routledge & Kegan
Paul, London, (trad. it. La società aperta e i suoi nemici,
Armando Editore, Roma, 2002).
- (1979), Die Beiden Grandprobleme der Erkenntnistheorie,
J.C.B. Mohr, Tübingen, (trad. it. I due problemi fondamentali
della teoria della conoscenza, Il Saggiatore, Milano, 1997).
Popping R. (1997), «Computer Programs For The Analysis of
Texts And Transcription», in Roberts C.W. (eds.), Text Analysis
for the Social Sciences. Methods for Drawing Statistical Inferences
from Texts and Transcription, Lawrence Erlabaum Associates,
Mahwah, New Jersey, pp. 209-211.
Ricolfi L. (a cura di) (1997), La ricerca qualitativa, Carocci,
Roma.
Rositi F. (1989), «Lamore folle fra analisi del contenuto
e computer», in Bellelli G. (a cura di), Il metodo del discorso.
Lanalisi delle produzioni discorsive in psicologia e in psicologia
sociale, Liguori Editore, Napoli, pp. 107-114.
Seale C. (2000), «Luso del computer nellanalisi dei dati
qualitativi», in Silverman D. (2000), Doing Qualitative Research.
A practical guide, Sage Publication, London (tr. it. Come
fare ricerca qualitativa, Carocci, Roma, 2002, pp. 223-248).
Silverman D. (2000), Doing Qualitative Research. A practical
guide, Sage Publication, London (tr. it. Come fare ricerca
qualitativa, Carocci, Roma, 2002).
Sofia C. (2005), Analisi del contenuto, comunicazione, media.
Franco Angeli, Milano.
Strati A. (1997), «La Grounded Theory», in Ricolfi L. (a cura
di), La ricerca qualitativa, Carocci, Roma, pp. 125-163.
Thomas W.I., Znaniecki F. (1920), The Polish Peasant in Poland
and America (trad. it. Il contadino polacco in Europa e in
America, Edizioni Comunità, Milano, 1968).
Tuzzi A. (2003), Lanalisi del contenuto. Introduzione ai
metodi e alle tecniche di ricerca, Carocci, Roma.
Weber P.R. (1990), Basic Content Analysis, Sage Publication,
London (trad. it. Fondamenti di analisi del contenuto, Sigma
Edizioni, Palermo, 1995).
Zipf G.K. (1935), The Psychology of Language. An introduction
to Dynamic Philology, Houghton-Mufflin, Boston.
NOTE
1] I nomi delle categorie
date sono qui solo esemplificativi. Lo stesso dicasi per le
parole utilizzate negli esempi successivi.
2] Nella bibliografia è sempre
riportata ledizione originale del testo ed eventualmente
la relativa traduzione italiana. I riferimenti alle pagine
sono da intendersi a questultima, se esistente.
 DOAJ
Content
DOAJ
Content
newsletter subscription
www.analisiqualitativa.com